一个时序元数据引擎的实现复盘:从双层 MemTable 到流式合并
沉淀一下从零实现 MetaStorage 元数据存储内核的心得体会,记录从 0 到 1 的开发全历程
MetaStorage 不是一个追求通用性的数据库内核,而是一套面向 “时序数据文件元数据检索” 场景、参考 LSM Tree 思想深度定制的存储引擎。
在项目初期,我们也曾尝试过 MySQL、DuckDB 等成熟方案,但在面对 PB 级元数据压力和严酷的查询性能要求时,通用组件的短板逐渐显现。下表简单对比了三者的差异:
| Key | MySQL | DuckDB | MetaStorage (本项目) |
|---|---|---|---|
| 定位 | 通用型关系数据库 (OLTP) | 嵌入式分析型数据库 (OLAP) | 时序 DB 元数据专用存储引擎 |
| PB 存储性能 | 分库分表运维成本高 | 内存消耗严重 | 数据可按照垂直&水平双维度切分 |
| 时间范围查询 | 慢查询性能受限 | 查询速度受写入事务影响 | 借助时间分区剪枝 (Pruning),PB 级检索秒级响应 |
| 数据变更/并发 | 高并发写入吞吐受限 | 数据更新时性能衰减明显 | LSM Tree 天生适配高频追加与合并,无锁写入 |
| 可定制与观测 | 二开成本高昂 | 内部实现较为黑盒 | 全链路可观测,深度定制 SLO 监控指标 |
该项目的目标很明确,主要解决的是 “时序数据库有海量的底层数据文件 (PB 级), 查询要按时间范围、命名空间等条件快速拿到文件元数据” 这类问题,主要有以下几点:
- 根据时间范围,从需要访问的海量元数据中,快速筛一组选到需要访问的数据
- 支持数据的垂直和水平扩展,避免单点数据压力
- 支持数据多版本并发 Insert 更新,避免数据写入影响查询速度
就我们的场景而言,每一条元数据记录的是时序数据库底层文件的 MetaData,具体的包括 file_id, object store path, start_time, end_time 等等。
为了支持元数据的多版本写入与查询可见性控制,我们在上述 MetaData 基础上新增了 version, operation, is_deleted 等字段。
从结果上看,MetaStorage 在存储、合并、MemTable、流式合并这些方向上已经形成了一套比较完整的工程实践。当然,目前它也有一个非常清晰的限制:“元数据 Schema 目前还是 hard code 的,还没有走到可扩展 Schema 的那一步”。
为什么参考 LSM 设计概念
现在很多大数据系统,底层都不是把数据成一条条记录去直接检索,而是先落成文件,再围绕文件做组织和查询。业务真正需要频繁访问的,往往不是文件内容本身,而是这些文件的元数据信息,比如:
- 文件属于哪个 namespace、哪个 table
- 文件覆盖的时间范围
- 文件大小、行数、对象存储位置
- 文件是否已经过期、是否被更高版本覆盖
MetaStorage 本质上就是想把 “文件元数据” 这件事单独做成一层存储引擎,之所以参考 LSM Tree,是因为这个问题天然就带有几个很典型的特征:
- 删除,写入频繁:适合批量写,批量删。将删除操作修改为“高版本的插入操作 + delete tomb 机制”
- 查询经常带时间范围:可自定义时间分区降低查询成本
- 历史数据会持续累积:需要后台不断合并 merge
所以最后落成的形态,就是 MemTable + L0 + L1 + 后台 Compaction 这一套结构。
为什么没有自己做 SSTable,而是直接用了 Arrow / Parquet / DataFusion
这个项目里一个很重要的取舍是:没有从零去实现一套复杂的底层 SSTable,而是直接建立在 Arrow、Parquet、DataFusion 这套生态上。
这是一个非常现实的选择:
- 自己开发 SSTable 意味着要自己处理文件格式、过滤、序列化、读取计划、bloom-filter,工程成本也非常高。
- 我们已经在二开 TimeSeries DB 内核,它使用 DataFusion 支持 SQL 查询能力。我们选择 DataFusion 的技术成本较低。
有了这套基础设施,很多事情就不用从头发明一遍了。项目里查询 MemTable 时直接走 DataFusion SQL,读取磁盘文件时也可以直接复用 Parquet reader;序列化存储 Parquet 文件时,还能直接配置 bloom filter、字典编码、排序策略和 page 级统计信息。
换句话说,这个项目更像是在 Arrow / Parquet / DataFusion 之上搭一套 LSM 风格的数据组织方式,而不是完整的重新造一套底层文件的轮子。
架构总览
flowchart TB
Client["Write / Query Requests"] --> Engine["MetaStorage"]
Engine --> Mem["MemTable"]
Mem --> Mutable["MutableMemTable<br/>active batch + frozen batches"]
Mem --> Immutable["ImmutableMemTable<br/>partition snapshots"]
Immutable --> Serializer["ParquetSerializer"]
Serializer --> L0["L0 Parquet Files<br/>time ranges may overlap"]
Engine --> Query["Query Path"]
Query --> ReadMem["MemTable Query"]
Query --> ReadL0["L0 Query"]
Query --> ReadL1["L1 Query"]
ReadMem --> GlobalDedup["Global Version Dedup<br/>+ tombstone/to_delete filtering"]
ReadL0 --> GlobalDedup
ReadL1 --> GlobalDedup
Compactor["Compactor"] --> L0
Compactor --> Partition["Partition by time window"]
Partition --> Merge{"Existing L1 file?"}
Merge -->|"No"| NewL1["Create new L1"]
Merge -->|"Small L1"| InMemory["In-memory merge"]
Merge -->|"Large L1"| Streaming["Streaming merge"]
InMemory --> NewL1
Streaming --> NewL1
L0 --> Manifest["Manifest"]
NewL1 --> Manifest
Manifest --> Managers["ManifestManager / ParquetManager<br/>atomic snapshot + lazy upload/delete"]
如果按职责来拆,可以概括成下面几层:
MetaStorage:统一对外接口,负责把写入、查询、合并几条主链路串起来。MemTable:承接内存写入,并负责把写入流量分层缓冲。L0:磁盘上的原始地层,允许时间范围重叠。L1:按时间分区组织的稳定层,适合长期查询,可按照小时,天级别配置时间分区。Compactor:后台持续整理 L0,产出新的 L1。Manifest:记录底层 parquets 文件列表,版本号。ManifestManager / ParquetManager:处理 manifest 和 parquet 文件的落盘、文件上传和延迟删除。
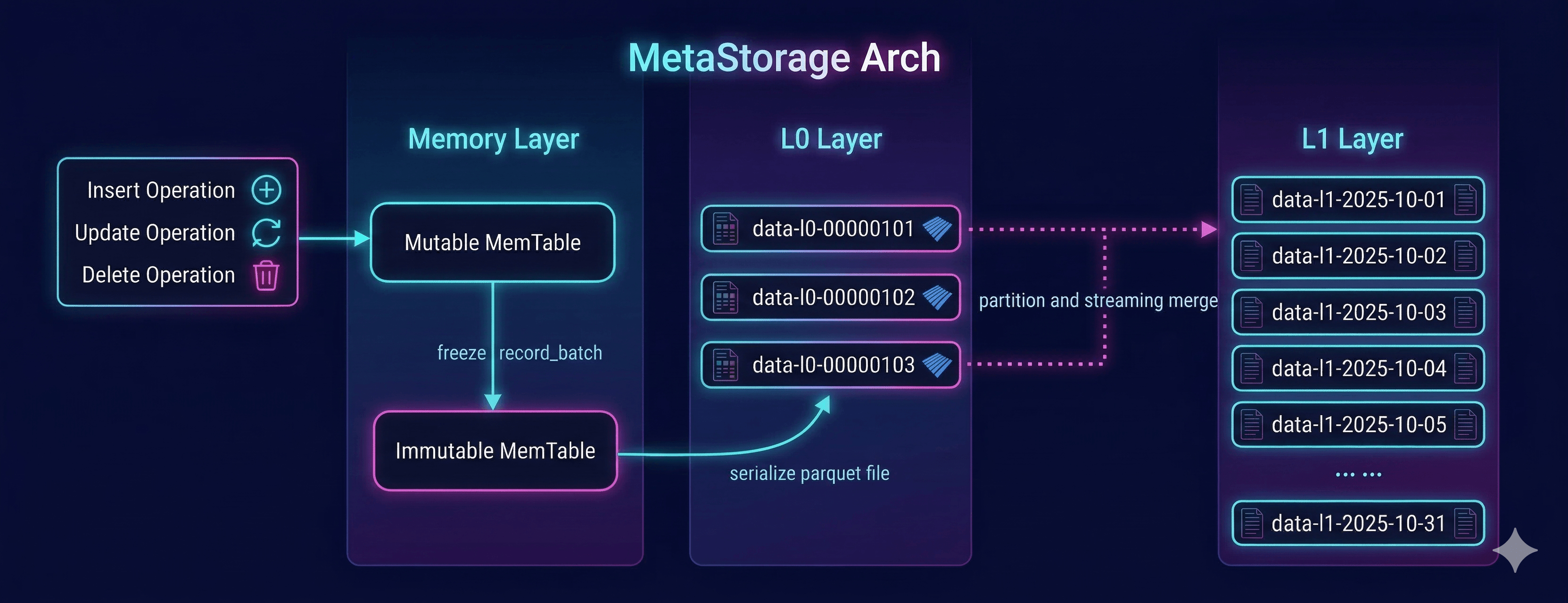
双层 MemTable 的设计
存储引擎采用双层 MemTable,并不只是为了让架构看起来更像 LSM Tree。更现实的原因其实是为了提升写入性能,降低写入操作对查询的性能影响。
如果只维护一个不断膨胀的内存表,那么每次写入、去重、整理都会越来越越重,查询也更容易被热点写入影响。于是最后我们采用了双层 MemTable 的方式,把内存层拆成两部分:
MutableMemTable:负责当前热点写入。ImmutableMemTable:负责接住一批已经相对稳定的数据,等待刷盘。
MutableMemTable: 热点写入缓冲
MutableMemTable 里又拆成了:
active_batchfrozen_batches
新的记录先和 active_batch 合并,然后基于 id + version 做一轮局部 compact。整理之后:
- 满批次的 RecordBatch 进入
frozen_batches。 - 不满的尾批次继续留在
active_batch。
这个设计带来的收益很直接:
- 热点写入始终只在很小的一块数据上发生。
- 稳定 batch 可以直接作为后续 Flush 的输入。
- 在真正落盘之前,内存层已经提前做了一轮局部去重。
所以双层 MemTable 这件事,一方面确实是在借 LSM 的思路,另一方面更重要的是,它确实提升了写入路径的稳定性和吞吐。
ImmutableMemTable: 从写缓冲到刷盘缓冲
当 MutableMemTable 中冻结 batch 的总量达到阈值以后,这些 batch 会整体移动到 ImmutableMemTable。
ImmutableMemTable 不是简单的“第二个内存表”,它更像是一个只读缓冲层:
- 内部按 partition 维护只读 batch 集合。
- 达到分区数量上限时触发 finalize。
- 或者超过一定时间间隔触发 finalize。
一旦 finalize,所有数据会被合并、排序、序列化成新的 L0 Parquet 文件,并注册到 Manifest 里。这一步和经典 LSM Tree 里的 MemTable flush 非常像,只不过这里落下的不是自定义 SSTable,而是 Parquet。
L1 层时间分区的设计
存储引擎的另一个很关键的设计,就是 L1 级别的时间分区。这是基于实际的业务场景 + 数据分布特点思考到的设计方案,我们几乎 100% 的用户在查询时序数据时都会指定时间范围,而且这个时间范围有时候会非常短,有时候又会很长。
比如有的查询只看最近 10 分钟,有的查询看 8 小时、24 小时,甚至更长。如果不做时间分区,或者把分区做得很大,比如一个文件直接覆盖一整天甚至更久,那么查询 10 分钟数据的时候,DataFusion 仍然得去加载一个很大的 Parquet 文件,哪怕最终只命中其中很小一部分数据,整体 overhead 也会很高。
所以这里的设计重点不是“按时间分区看起来很标准”,而是:
- 让短时间范围查询尽量只碰到少量文件。
- 让长时间范围查询依然可以通过多文件并行完成。
- 把大文件读取的固定成本切小。
当前实现里,partition_duration 是可配置的,默认情况下我们可以直接按照天进行分区,相同时间段内的数据进行多版本合并也非常容易。
查询链路
查询这条链路,实际上做过多轮调整。真正难的点不在于“能查到数据”,而在于“多层数据一起查时,结果是不是全局正确”。因为同一条记录可能同时存在于:
MutableMemTableImmutableMemTableL0L1
而且不同层中可能保留着同一条记录的不同版本,甚至包含 tombstone 标记。所以最后我们把查询链路收敛成了下面这个思路:
- 并发查询 MemTable、L0、L1 三层。
- 先拿到所有候选结果。
- 在引擎层做全局去重,只保留最新数据版本。
- 再处理
tombstone。
这里有一个细节很重要:删除标记不能过早过滤。因为如果上层 tombstone 还没来得及覆盖掉下层旧版本,就把 tombstone 丢掉了,查询结果就会出错。
这块之所以最后能稳定下来,其实离不开 DataFusion。文件内过滤、MemTable SQL 查询、RecordBatch 合并这些事情都能直接复用成熟能力,不需要自己在底层文件格式上做太多额外工作。
Compaction OOM 陷阱 🪤
Compaction 是这套引擎里最像 “系统工程” 的部分。
L0 文件一多,系统就不能一直堆在那里不管,必须有后台线程持续把它们整理成更稳定的 L1 文件。整体流程大致如下:
flowchart LR
L0Files["L0 files reach threshold"] --> ReadL0["Concurrent read L0 files"]
ReadL0 --> KeepTombstone["Deduplicate L0<br/>but keep tombstones"]
KeepTombstone --> Split["Partition by time window"]
Split --> EndPoint1(("..⬇️.."))
flowchart LR
StartPoint2(("..⬆️..")) --> PickL1["Find latest L1 for each partition"]
PickL1 --> Decision{"L1 row count >= threshold?"}
Decision -->|"No"| InMem["In-memory merge"]
Decision -->|"Yes"| Stream["Streaming merge"]
%% ... 后续逻辑
朴素的 Compaction 初始设计
最早的思路并不复杂:
- 把 L0 读出来。
- 按时间窗口做分区。
- 找到对应分区的 L1。
- 直接在内存里 merge。
- 去重、过滤、写回新的 L1。
在数据量还不大的时候,这样做完全能工作,而且路径简单。
PB 级数据对 Compaction 的考验
真正的问题出现在数据量继续增大之后。
当某些 L1 文件已经足够大时,如果仍然按“整文件读入内存再合并”的方式处理,内存压力会非常明显,最后直接把流式合并这条链路逼出来了。换句话说,StreamingMerger 不是一开始拍脑袋设计出来的,而是后来在大数据量场景为了应对 OOM 的问题,才进行的优雅优化。
流式合并的设计经验
最后落实下来的 StreamingMerger,它的核心思路是:
- 先把 L0 记录按
end_time字段排序。 - L1 不整文件读入,而是针对大的 parquet 进行多 batch 读取,多 batch 合并。
- 每一轮根据当前 L1 批次的时间上边界,取出对应范围内的 L0 记录。
- 把这部分 L0 和当前这部分 L1 合并、去重。
- 结果按配置的 row group 大小持续写出。
这样做之后,系统不再需要把整个大 L1 一次性塞进内存,合并和写出可以边读边做,内存占用就稳定了很多。
另外,我们需要在合并的过程中去处理 tombstone 标记。
在读取多个 L0 文件并准备下沉到 L1 之前,系统会先对 L0 做一次去重,但这里保留 tombstone,不会提前删除。原因很简单:
- 上层的删除版本必须继续往下传播。
- 否则下层旧版本会失去被覆盖的机会。
而到了 L0 与 L1 真正完成合并之后,系统才会执行 deduplicate_and_purge,把已经可以安全清理的逻辑删除和过期记录物理丢弃。这个顺序听起来只是实现细节,但实际上决定了整个多层可见性语义是否正确。
存在感不强,但是很重要的 Manifest
除了写入和查询主链路之外,这个项目还有一个“平时不显眼,但不能没有”的基础设施 — Manifest。
Manifest 负责维护当前有哪些 L0、L1 文件,它们的层级、大小、行数、时间范围和删除状态是什么,在我们的元数据引擎关闭之后,可以通过读取 Manifest 完成底层数据文件校验,重新启动,完成状态恢复。
另外我们的 Manifest 在更新时,采用原子更新的策略,磁盘上旧的 parquet 文件在被更新后,不会立刻删除,而是先在 Manifest 中标记,再交给 ParquetManager 延迟处理。
这个设计看起来保守,但非常有必要。因为 Compaction 本身就是“新文件生成、旧文件失效”的切换过程,延迟删除相当于给这段切换留了安全窗口,可以避免文件状态变更时序不一致的风险。
总结
我们不能把 MetaStorage 作为一个通用数据库去看,它当然还远远没有走到那个阶段;但如果把它放回到“时序文件元数据存储与检索”这个问题看,这个项目已经把一条很完整的主链路做出来了。
这里面有双层 MemTable,有 L0 / L1 分层,有基于时间范围的分区,有多版本标记和 tombstone 语义,也有从 OOM 问题里迭代出来的流式合并;再往下,还有 Manifest、延迟删除、benchmark 驱动迭代这些更偏工程落地的部分。
所以对 MetaStorage 更准确的描述不是 “实现了一个 LSM Tree”,而是:围绕时序文件元数据场景,做出一套参考 LSM 思想、建立在 Arrow / Parquet / DataFusion 之上的专用存储引擎。
它现在最值得继续推进的方向也很明确:把固定的 Schema 逐步抽象出来,只有把这些能力抽象出来,这套引擎才会真正从“面向当前时序元数据场景的实现”走向“可以复用的框架”。让这套已经在存储、查询、合并上打磨过多轮的能力,未来可以服务更广一点的文件元数据场景。