👆向上封装具备多级路由的元数据服务 -- MetaServer
记录下 MetaServer 分布式服务开发的经验
在前文《一个时序元数据引擎的实现复盘:从双层 MemTable 到流式合并》中,我们构建了一个针对时序元数据场景深度优化的存储内核。本文将探讨如何将其向上抽象,封装为具备 API 访问能力的分布式服务。
从项目的职责边界来看,我们可以这样进行区分:
| Key | 定位 |
|---|---|
| MetaStorage | 内核存储层,负责 PB 场景下元数据的高性能写入、压缩、落盘和检索。 |
| MetaServer | 服务层,负责把这颗存储内核包装成可部署、可路由、可恢复、可扩展的分布式服务。 |
两个项目的目标是相同的:解决 PB 级数据场景下的元数据的存储和检索问题。
MetaServer 的定位并非重新发明存储,而是为 MetaStorage 构建一层适配线上环境的服务外壳。系统的核心存储复杂度依然收敛在 MetaStorage 内部。
🤔 为什么还需要 MetaServer 这一层
MetaStorage 已经解决了单容器节点的核心存储问题,但只靠存储内核本身,还不足以直接支撑线上元数据服务。要把它真正用起来,还需要补齐下面这些能力:
- 统一的 HTTP API,对外暴露稳定的服务接口。
- 多实例部署下的请求路由能力。
- 大数据量下的水平和垂直切分能力。
- 服务重启后的本地恢复和 MySQL 回灌能力。
- 与 compactor 协同工作的节流、观测和故障处理能力。
所以 MetaServer 的职责并不是替代 MetaStorage,而是把内核存储能力组织成一个可以稳定对外服务的集群形态。
🎯 二级路由是 MetaServer 的核心设计
在 MetaServer 的服务层设计中,最关键的决策并非 API Trait 的抽象,也不是同步逻辑的实现,而是二级路由(Two-Tier Routing)机制。
通过引入 user_id 与 file_id 的双层路由体系,我们实现了从 “业务隔离” 到 “物理分片” 的精准映射:
- 一级路由:
user_id→server-group- 定位:垂直切分与多租户隔离。
- 作用:按用户维度将请求分发至特定的服务组,实现 Namespace 级别的业务隔离与热点打散。这确保了不同用户间的数据分布互不干扰,为资源配额和 SLA 保证提供了物理基础。
- 二级路由:
file_id→server-shard- 定位:水平切分与负载均衡。
- 作用:在服务组内部,利用 file_id(基于 MySQL 自增主键)进行取模运算,将元数据均匀散列到具体的物理分片(Shard)上。
二级路由(Two-Tier Routing)的核心价值是:收敛查询与均衡写入
- 收敛查询: 对于 PB 级元数据检索而言,系统开销往往不在于单次点查,而在于“查询不精准导致的无效全量扫描”。二级路由在请求触达
MetaStorage之前,就已将其限制在极小的物理范围内,充分释放了底层存储的局部查询性能。 - 均衡写入: 在写入侧,该机制能均匀分散高并发写入压力。针对超大规模租户,我们可以通过增加水平资源(Shard 数)来线性提升其处理能力。
🚀 查询加速的本质:将查询代价编码进路由策略
针对 query_file_metadata 等核心 API 请求,Router 层显式定义了三条执行路径,其查询开销随条件的缺失呈阶梯式增长:
- 路径 A, 精确命中(
user_id+file_id): 直接映射至单个物理 Shard。这是最廉价且最高效的执行路径,实现了点对点的精准检索。 - 路径 B, 组内聚合(仅
user_id): 路由至对应的 Server-Group,随后在组内执行并发广播(Broadcast)并收敛结果。代价适中,受限于组内最慢分片的响应时间(Tail Latency)。 - 路径 C, 全局扫描(无
user_id): 被迫退化为全集群范围的 Fan-out 广播与全局聚合。这是代价最高的路径,通常作为保底方案或低频管理查询使用。
这套方案的设计哲学是:它使用简单的路由策略做到了写入均衡和查询收敛,我们在 router 层直接把查询代价编码进了这套二级路由策略。
- 确定性性能:查询条件越完整,路径越短,速度越快。
- 局部性红利:查询越聚焦,越能避免无效的 IO 和网络开销。
- 优雅降级:当查询条件不完整时,系统自动退化为分片合并模式(Fan-out),确保了功能的完备性。
这正是二级路由设计最契合本项目的地方,它并不追求理论上的“通用最优”,而是通过一种高度贴合业务场景的查询模型,强制引导高频请求走在最廉价的路径上。
🪜 架构视图
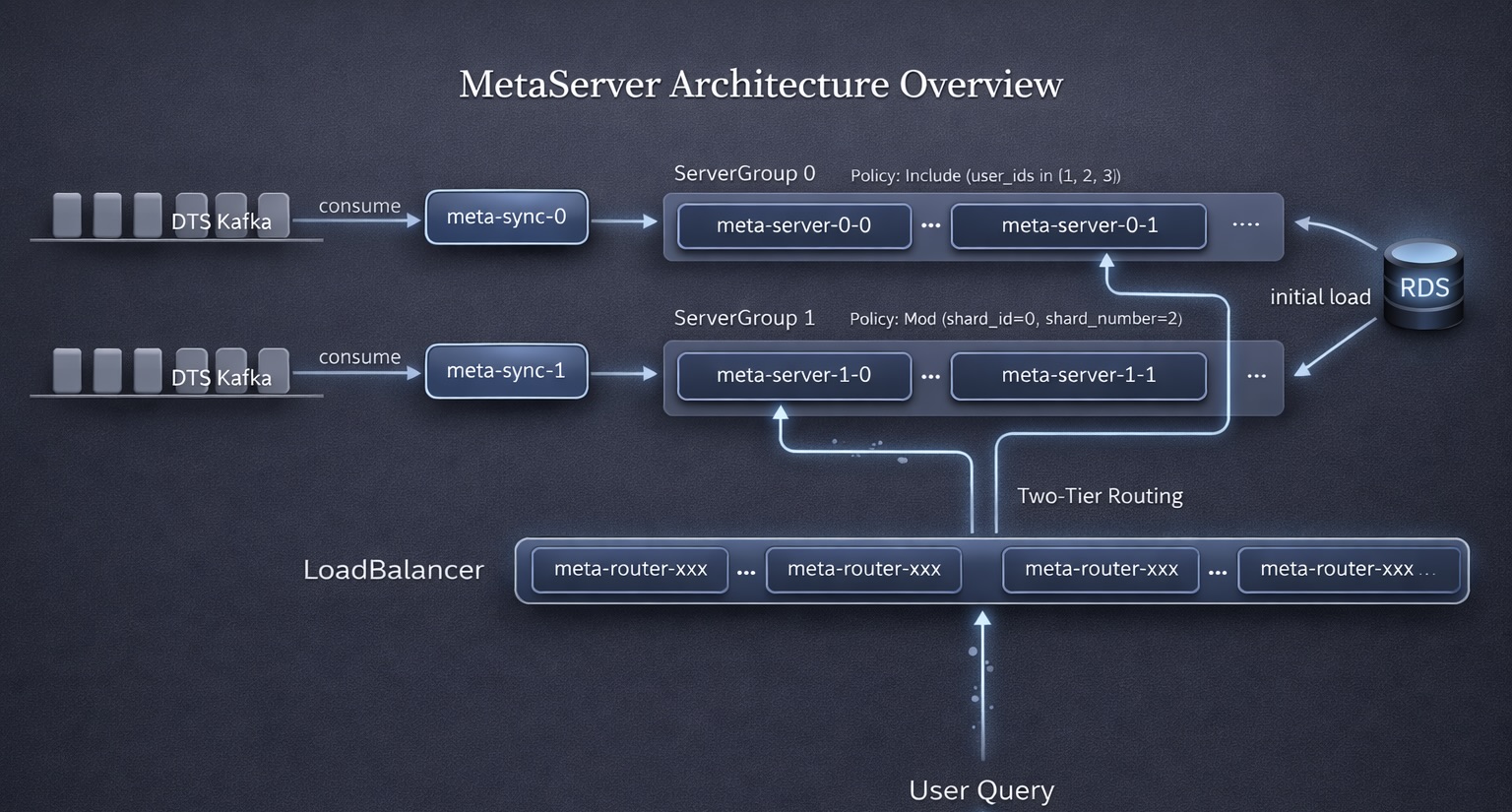
查询链路:
- 用户请求进入
router,通过二级路由命中目标server-shard,最后由该 shard 内部的MetaStorage完成检索。在线查询不会直接走 MySQL,MySQL 在这里更多承担原始数据源和恢复来源的角色。
写入链路:
- 全量同步:
MetaServer启动后会先尝试基于本地 manifest 和数据文件恢复MetaStorage,然后再从 MySQL 按file_id递增拉取历史数据,过滤出当前 shard 负责的部分并写入MetaStorage。如果 PVC 被重建、本地数据丢失,就不能再依赖 manifest,只能从 MySQL 重新完成一次从 0 到 1 的构建。 - DTS 增量更新: MySQL 的 binlog 经过 DTS 进入 Kafka,再由
MetaSyncer消费并转发到对应的MetaServer。MetaSyncer本质上只是增量同步服务,负责消费消息、按同样的分片规则路由,再把 insert、update、delete 操作送到目标 shard。只有在MetaServer完成初始化加载后,增量链路才会开始工作,这样可以保证系统先完成存量构建,再继续追平后续变更。
⚖️ 存储感知的协同机制(Storage-Awareness)
这个项目还有一个容易被忽略,但其实很重要的设计点:服务层并没有把 MetaStorage 当成一个无限吞吐的黑盒。
在历史数据从 MySQL 回灌到 MetaStorage 时,服务层会观察 L0 文件数量。如果 L0 堆积超过上限,就会主动等待 compactor 工作 cool down 下来,等 L0 数量回落后再继续写入。
这件事说明当前架构并不是简单地“把请求转发给内核”,而是明确考虑了内核的工作节奏和容量边界。对 LSM 体系来说,这种协同非常重要,因为系统性能不仅取决于查询接口设计,还取决于写入、落盘和 compaction 是否处在一个平衡状态。
从这个角度说,MetaServer 的价值不只是把 MetaStorage 暴露成 HTTP 服务,更是在服务层补齐了与存储内核优雅配合的那部分工程逻辑。
📊 复盘与展望:以简御繁的工程取舍
回看 MetaServer 的演进,其核心逻辑可以概括为:MetaStorage 负责“存、压、查”的内核深度,而 MetaServer 负责“扩展、路由、集群化”的分布式广度。 我们并没有试图构建一个通用的全功能元数据平台,而是针对“PB 级元数据”且“查询条件可约束”的特定场景,提供了一个极致的工程化答案:
-
多维弹性:通过 Server-Group 实现租户级的隔离与垂直扩展,通过 Server-Shard 实现数据容量的水平横向扩展。
-
确定性性能:二级路由将查询代价直接编码进路由策略,强制引导高频请求走在最廉价的路径上,从而在分布式环境下依然保留了底层内核的局部性红利。
MetaServer 的价值不在于它有多复杂,而在于它通过一层足够轻量的封装,成功将单机存储内核转化为具备无限扩展能力的元数据服务集群。在未来的演进中,这一“向上封装”的思路也将继续指导我们接入更多元数据表(Store),构建更完整的分布式元数据存储服务体系。