文本检索场景下的分布式索引设计
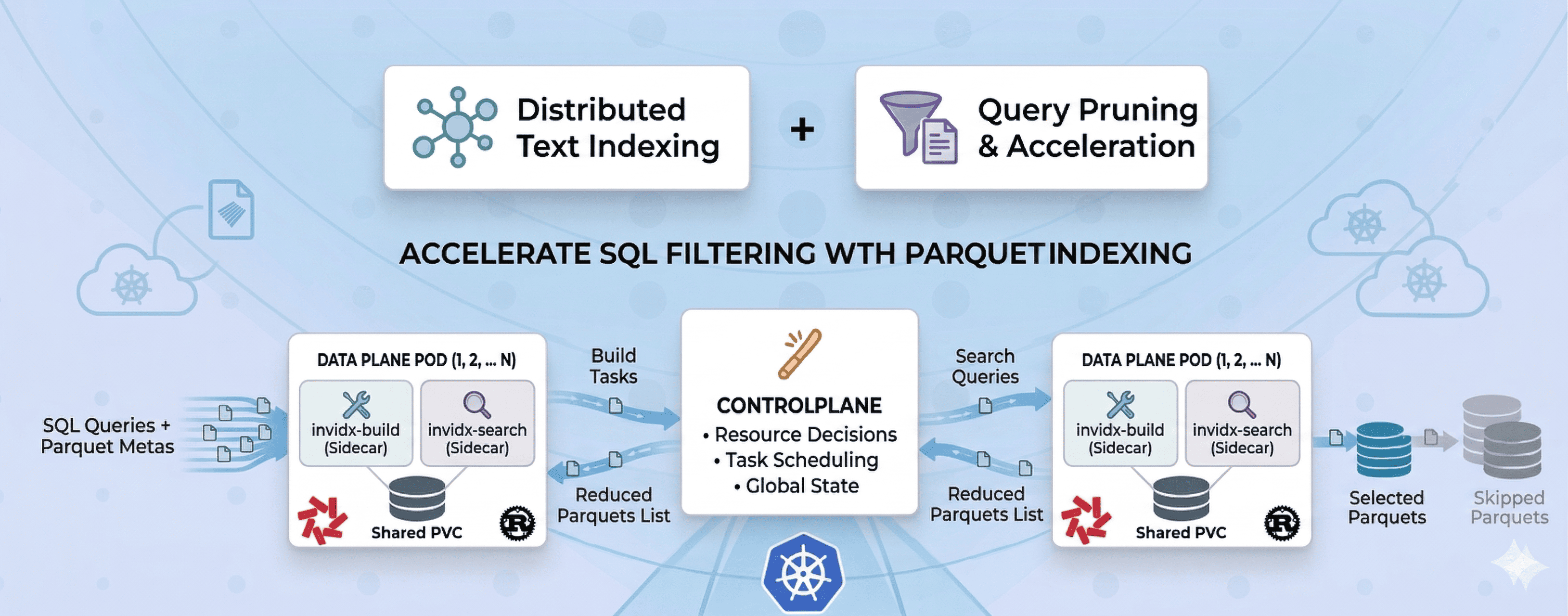
本文详细记录了 2025 年为推动基研 Rust 生态建设,从 0 到 1 的分布式索引项目的设计与实现过程。
该项目需要解决的问题非常具体:为基于 Parquet 数据文件存储的 TimeSeries DB 做查询加速。
上游 SQL 通常会先给出一个时间范围,如果数据库直接按这个时间窗口去扫描,就很可能把时间窗口里的全部 parquet 都访问一遍。我们的目标不是替代数据库执行 SQL,而是在真正读取这些 parquets 之前,先用一层索引服务把候选文件集尽量缩小,降低查询开销(用户通常只需要返回 limit k 条数据,我们无需真正访问所有底层 parquet 文件)。
我们可以把该项目理解为一层 “SQL 查询前置裁剪服务”。它可以通过接收来自上游 TimeSeriesDB 的过滤条件、时间范围和候选 parquets 集合,输出更小的一批值得访问的 parquets 集合,同时把 can_skip, not_found, timeout 的 parquets 文件分类返回。
这样后面的设计重点就会非常明确:围绕 parquets 集合裁剪、时间过滤和服务化运行去做系统设计。
🛠️ 索引内核选择 – Tantivy
底层索引库我最终选的是 Tantivy1。这个选择对整个项目影响很大,具体选择它的理由如下:
| 关注点 | 我为什么最终选择它 |
|---|---|
| Lucene 平替 | 能力对标:Rust 生态中功能最成熟的全文检索库,抽象模型与可靠性对标 Lucene。 |
| Rust 生态 | 同构工程:消除跨语言(FFI)边界,实现索引构建、查询与服务化在同一 Rust 工程栈闭环。 |
| 深度定制 | 高扩展性:支持自定义 Tokenizer、Collector 及列 id 映射,满足非“黑盒”化改造需求。 |
| 二次开发 | 源码掌控:作为 Tantivy 的 Contributor2,我们可以针对 Tantivy 内部行为进行深度参与。 |
还有一个我非常实际看重的点是 mmap。这个项目不是建完索引就结束,而是建完之后还要长期驻留、反复加载、反复查询。Tantivy 的 mmap 能力可以让我比较自然地把单个 DataPlane 上的索引做成“落盘后即可加载、可长期复用”的模型,而不用额外再复制一层索引内容到自定义内存结构里,反而这样会更加消耗内存。
简而言之,我们需要的不是一个只能拿来搜索 demo 的库,而是一套既适合 Rust 工程、又支持 mmap、还能继续深度定制和长期维护的倒排索引底座,而 Tantivy 正好符合这个要求。
🗺️ 确定分布式索引系统的边界
在进入具体架构之前,我其实先做了一件事:明确这套系统的边界。
我不想让它变成一个“大而全的索引平台”,也不想让它和上游数据库在职责上重叠。所以一开始我就为这个项目赋予了明确的边界职责:
- 它负责在 TimeSeriesDB 真正查询前,缩小候选 parquet 集合范围。
- 它不负责替代上游 TimeSeriesDB 执行最终 SQL。
- 它将待筛选的 parquets 集合分类进行返回,为上游 TimeSeriesDB 提供 parquets 访问决策。
这个边界非常重要,因为它直接决定了后面很多设计不会往 “数据库内核替代品” 那个方向跑偏。比如:
- 我不需要把所有 SQL 语义都搬进来。
- 我可以重点优化时间范围、字段条件和
limit带来的裁剪收益。 - 我可以把更多精力放在索引生命周期、资源调度和服务化能力上。
也正因为这样,后面我才会很自然地把这套系统拆成 ControlPlane 和 DataPlane 两层,而不是做成一个单体索引节点。
👀 视角转变:从 ClickHouse 到 TimeSeriesDB
在做这个项目之前,我其实已经有过 ClickHouse 索引相关的经验。当时比较自然的思路是:在一个 DataPart 内部做索引构建,然后在查询时利用这个局部索引去加速扫描。这个思路放在 ClickHouse 里是很有用的,因为它的数据组织方式和执行路径天然就是围绕 DataPart 展开的。具体可以参考此前写的 《在向量数据库中增强文本检索 – MyScaleDB 》
但本次的问题场景改变了。这次不是“几个 DataPart 怎么加速”,而是“海量 Parquets 文件怎么收敛访问开销”。 也就是说,我们不能再沿着“单个数据块/单个文件内部建索引”的视角看问题了,而要把视角抬高到系统层面:
- 索引不应该在单个 Parquet 上建立,不要在行级或者 RowGroup 级别的过滤做过多的无用功。
- 单个 Parquet 文件存储的数据量较小,我们可以使一个索引覆盖一组 Parquet 文件。
- 索引构建不应该只是单机行为,可以通过分布式构建提升任务吞吐量。
- 查询也不应该只看单个局部索引,而应该能够在多个 DataPlane 上并行执行。
从这个角度看,整个问题实际上发生了一次视角转换:
- 从 “单个 Parquet 文本索引” 转到 “多 Parquet 单索引”。
- 从 “文件内部优化” 转到 “全局 Parquet 访问面优化”。
- 从 “数据库内核内部能力” 转到 “独立索引服务能力”。
这次视角转换带来的收益很明显。因为一旦索引能力从数据库内核中脱离出来,变成一个独立服务,我就不再只局限于“怎么建索引、怎么查索引”,而可以把更多系统工程层面的能力一起做进去,比如:索引 TTL、资源调度、弹性伸缩、ControlPlane / DataPlane 分工、以及多个 DataPlane 的并行索引构建和并行查询。
🏗️ 架构设计:ControlPlane + Multi DataPlane
我最终采用的是典型的一控多 DataPlane 结构,下面是架构的描述图。
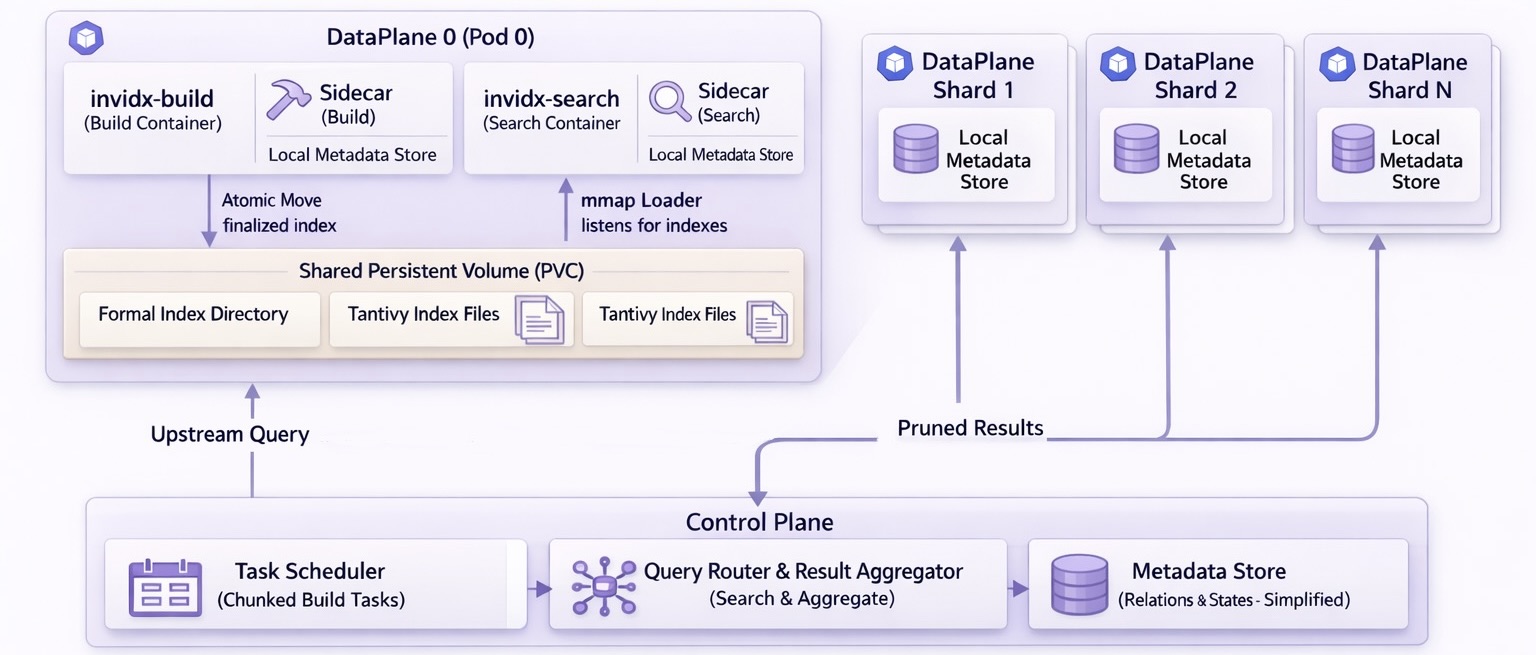
这套架构里,核心边界很清楚:
control-plane不亲自建索引,也不直接执行索引查询。它负责从元数据服务拉取时序 Parquet 信息,封装成索引构建任务并发送给 data-plane。- 每个
data-plane-{shard_id}都是一个自治的数据平面单元,里面有invidx-build和invidx-search两个组件,以 sidecar 方式共享一块 PVC。 control-plane通过元数据和 RPC 去编排 DataPlane,而不是替 DataPlane 执行内部工作。拆成多个 DataPlane 之后,查询和构建都可以并行展开。
DataPlane 的 Sidecar 设计理念
在项目早期迭代的过程中,我们走过一条更传统的路径:invidx-build 先把索引产出到本地,再把这些产物上传到 S3,作为构建侧和查询侧之间的中转站;invidx-search 再周期性地从 S3 拉取可用索引。这个方案不是不能工作,但链路很长。除了文件复制本身,还要额外维护产物状态、元数据同步和加载时序,整个“构建完成 -> 可搜索”的过程会变得比较绕,也不够直观。
现在我把 invidx-build 和 invidx-search 放进同一个 DataPlane,并让它们共享一块 PVC 存储卷。这样做的核心价值,不是少了一个组件,而是把索引产物从“跨节点分发”重新收敛成“本地目录切换”。带来的直接收益是:
invidx-build完成落盘后,invidx-search可以直接感知和加载,只需要定期扫描正式目录即可。- 我不再需要维护一套额外的索引产物复制链路,正式切换通过原子移动完成,状态机也简单很多。
- 即使某个 DataPlane 发生故障,我也不依赖 S3 去保留一份中转副本,因为倒排索引的重建成本本身就比较低,恢复路径可以更直接。
- 索引从“构建完成”到“可搜索”的路径更短,排查时也更容易定位问题。
关于 K8s Sidecar 的详细介绍,可以参考 《K8s 官方文档 Sidecar Containers》
☸️ ControlPlane 的职责约束
我没有把 ControlPlane 做成一个单纯的请求转发器。它承担的是整个系统的全局决策、全局编排和全局状态收敛。
| Key | ControlPlane 内开发的逻辑 |
|---|---|
| 资源决策 | ScaleUp、ScaleDown、PVC 规格、index TTL 配置 |
| 索引构建任务调度 | Parquet 去重、Task 切分、容量探测、任务分发 |
| 查询策略生成与执行 | 查询路由、分组策略、Limit 下推、超时提前退出 |
| 生命周期控制 | 元数据同步、健康检查、清理和回收流程 |
资源决策
系统启动时,ControlPlane 首先要决定两件事:当前这个用户应该有多少个 DataPlane,以及每个 DataPlane 应该使用多大规格的 PVC。除此之外,扩容、缩容和 Index TTL 的规格控制,我也都放在这一层。原因很直接,这些决策都依赖用户历史流量、当前索引规模和整个集群的资源状态,单个 DataPlane 自己是看不全的。
索引构建任务调度
我把 Index Build Task 的生成和发送都放在 DataPlane。它从元数据服务拉取 Index TTL 范围内的 Parquet,判断哪些文件还没有被索引,再把这些 Parquet 切成更适合执行的构建任务,最后结合每个 DataPlane 的实时容量状态,把任务分发给合适的 DataPlane。这个职责之所以放在控制面,是因为只有它同时知道 “还有哪些数据没建索引” 和 “哪些节点现在还能接任务”。
查询策略生成与执行
查询时也由 ControlPlane 负责总控。它先根据本地元数据知道哪些 Parquet 落在哪些 DataPlane 上,再去拉取相关的 parquet_id -> index_file_id 关系,按时间顺序组织(index_file_id)检索策略,并在分布式查询过程中执行 limit 下推和超时提前退出。至于同列多条件的 BooleanQuery 拼接,则是在单个 DataPlane 内由 invidx-search 落地执行。这里的边界也很明确:策略在 ControlPlane,表达式执行在 DataPlane。
生命周期控制
扩容、缩容、元数据同步、健康检查这些能力我也都放在 ControlPlane。因为这些事情本质上都依赖全局状态,不适合让单个 DataPlane 各自做局部判断,否则很容易出现局部最优、全局失衡的情况。
⚙️ 初始化资源配置
用户首次配置索引服务时,需要为其初始化一定的资源配置,具体给多少资源,需要依赖一系列的评估动作。
既不能太少,也不能太多
初始化分配索引资源时,不能分配太少,也不能分配太多。分配太少,会让用户很快遇到扩容、排队和索引回补;分配太多,又会直接拉低集群资源利用率。
- 对小用户来说,一个最小规格的 DataPlane 往往就够了;
- 对大用户来说,如果只是无脑增加 DataPlane 数量,查询收益也不会一直线性增长,因为 RPC fan-out,Pod 数量过多会带来但用户资源 request 过高。
观察历史流量,再做真实索引估算
所以我没有直接拿 Parquet 大小去拍脑袋分配,而是先观察用户的历史流量状态,再执行一次真实的索引构建估算任务。这个估算过程会复用真实 schema、真实 tokenizer 和真实构建路径,目的是让容量判断更接近最终索引体积,而不是只看原始数据大小。
梯度选择 PVC 和 DataPlane 数量
拿到估算结果之后,我会结合配置的 Index TTL,反推出在这个保留窗口内大约需要承载多少索引数据,然后再套进预设的 PVC 梯度规则里,选出合适的单个 PVC 规格和 DataPlane 数量。我的目标不是追求理论最大并发,而是在容量安全、资源利用率和查询收益之间取一个更稳的平衡点。结果上就是:大用户会适当放大单个 DataPlane 的 PVC,减少整体 DataPlane 数量;小用户则尽量用最小资源起步。
⛓️ 构建链路:我怎么把 Parquet 变成索引
下面是索引的构建链路
flowchart LR
%% 第一行:控制平面逻辑
A["catalog parquets"] --> B["task generator"]
B --> C["filter indexed"]
C --> D["chunk by size"]
D --> E["DP selection"]
E --> F["send build task"]
F --> DOT1["..."]
%% 强制换行占位符(隐形连接线,确保上下对齐)
A ~~~ G
%% 第二行:数据平面逻辑
DOT2["..."] --> G["persist to SQLite"]
G --> H["worker reads"]
H --> I["build indexes"]
I --> J["move to PVC"]
J --> K["search discover"]
K --> L["mmap load"]
%% 样式处理:去掉省略号节点的边框和背景
style DOT1 fill:none,stroke:none,color:#888
style DOT2 fill:none,stroke:none,color:#888
统一索引构建的 “资源消耗单位”
我没有把一个索引构建 task 理解成“处理了几个 Parquet”,而是把它理解成一个更稳定的 “资源消耗单位”。因为只看 Parquet 个数是不够的,字段分布、分词器和内容差异,都会让最终索引体积相差很大。
所以我在 task 切分时会同时约束:
- 单个 task 包含的 Parquet 数量。
- 单列索引的预估体积。
- 整个 task 的总预估索引体积。
这样 task 才更像一个可调度、可估算、可落盘的资源单位,而不是一个简单的文件计数器。
对 DataPlane 做磁盘容量探测
ControlPlane 在为 task 选择 DataPlane 时,不是随机选,也不是简单轮询,而是先做一次容量判断:
flowchart LR
A["new build task"] --> B["collect DataPlane status"]
B --> C{"fits disk safety line?"}
C -- yes --> D["dispatch task"]
C -- no --> E{"can shrink task?"}
E -- yes --> F["split and retry"]
E -- no --> G["trigger scale-up"]
索引任务发送端会关注三个指标:
- 当前 pending task 是否已经过高。
- 当前 pending bytes 是否已经积压太多。
- 这个 task 预估的索引体积加进去之后,会不会把磁盘顶到安全线以下。
如果塞不下新的 task 任务,我们才会考虑 ScaleUp;如果只是当前 task 太大,我会先尝试缩小 task 再重试,而不是立刻扩容。所以我更愿意把这套逻辑描述成一个 “容量感知的任务分发器”,而不是一个普通的构建任务队列。
单个 DataPlane 内部的索引构建流程
在单个 DataPlane 里,invidx-build 的主流程是下面这条链路:
flowchart LR
A["persist task into SQLite"] --> B["read parquet files"]
B --> C["group columns"]
C --> D["convert record batch to Tantivy docs"]
D --> E["periodic commit"]
E --> F["finalize index"]
F --> G["atomic move to shared PVC"]
整体上是围绕 Tantivy 去写的一层 wrapper,主要做了下面这几件事:
- 先把 task 持久化到 SQLite。
- worker 开始读取 task 关联的 Parquet。
- 按列分组构建索引,而不是一次性把所有列全部打开。
- 把 RecordBatch 转成 Tantivy 文档。
- 周期性 commit。
- 最终 finalize,并把目录原子移动到特定路径,共享给 sidecar 的
invidx-search。
🔍 查询链路:我怎么把 “查全部 Parquet” 变成 “查必要 Parquet”
flowchart LR
%% 第一行:控制平面查询分发
subgraph CP ["ControlPlane Query Flow"]
A["upstream SQL + parquets"] --> B["control-plane"]
B --> C["route to DPs"]
C --> D["fetch index rels"]
D --> E["gen index_id groups"]
E --> F["search strategy"]
F --> DOT1["..."]
end
%% 隐形占位符确保上下对齐
A ~~~ Q1
%% 第二行:数据平面执行逻辑
DOT2["..."] --> Q
subgraph Q ["single DataPlane execution"]
direction LR
Q1["extract time range"] --> Q2["parse filter tree"]
Q2 --> Q3["resolve column IDs"]
Q3 --> Q4["run Tantivy query"]
end
%% 汇总返回
Q4 --> G["merge results"]
G --> H["return results"]
%% 样式美化
style DOT1 fill:none,stroke:none,color:#888
style DOT2 fill:none,stroke:none,color:#888
| Key | 描述 |
|---|---|
| 路由规则 | 根据上游传递需要裁剪的 parquets,寻找对应的 index-file 分布关系 |
| 时间范围 | 一级过滤条件,可结合其它查询条件组合为 BooleanQuery,也可单独过滤 |
| 过滤表达式解析 | 展开为 Tantivy 的 BooleanQuery |
| 渐进式查询 | 按照 index-files 数量,时间排序后依次递进检索 |
| 启发式 limit | 命中的函数超过 limit 一定的倍率,即可提前返回 |
路由规则
查询到 control-plane 之后,我的第一步不是立刻广播给所有 DataPlane,而是先用本地元数据把候选 Parquet 映射到具体 DataPlane 上的 index_id。这里的 index_id 本质上就是索引文件序号,可以理解为该索引覆盖数据的时间上界。只有先完成这一步,后面才知道该去哪些节点、哪些索引文件上做检索。
时间范围
用户查询都会带时间范围,所以我把它当成一级过滤条件。invidx-search 接到请求后,会先从 DataFusion 过滤表达式里提取全局时间范围,再决定哪些 reader 需要真正参与检索。这样一来,control-plane 可以按时间组织 index_id 的检索顺序,单个 DataPlane 也能先把搜索范围压小。
过滤表达式树状解析
我没有把 where 条件粗暴地摊平成一组字段谓词,而是保留它原本的布尔结构:
- 叶子节点表示单列多条件。
- 中间节点表示
AND和OR组合。
这样做的好处是,我可以把同列多条件尽量拼成 Tantivy 的 BooleanQuery,避免同一个 index_id 在树的不同分支上被重复扫描。
渐进式查询
这是我最看重的查询策略之一。拿到各个 DataPlane 返回的 index_id 之后,control-plane 会按时间顺序把它们组织成若干组。对 progressive search 来说,就是先查靠前的一组 index_id,再看累计命中是否足够,如果够了就提前停掉后续组。对于带时间排序和 limit 的查询,这个收益很直接。
启发式 limit
这里我没有直接拿 SQL 的裸 limit 当停止阈值,而是使用一个放大后的目标值,比如 rows = limit * mag_factor。原因是索引命中行数和最终 SQL 结果数并不完全等价,所以它本质上是启发式提前收敛,而不是严格裁剪。最终我返回给上游的,也不只是命中的 Parquet,还会区分 not_found、skip、timeout 等结果类别。
📦 DataPlane 内部索引 load & unload
在单个 DataPlane 内部,我没有让查询路径每次都去临时打开磁盘上的索引目录,而是让 invidx-search 长期维护已加载的 reader。
发现新索引就加载
单个 DataPlane 里的 invidx-search 内部有一个长期运行的加载器,它会持续监听正式索引目录:
- 监听正式索引目录。
- 发现新索引后创建加载任务。
- 把 reader 通过 mmap 方式加载进内存结构。
这样查询路径就不用每次重新新建 reader,而是直接复用长期驻留的 reader。内部我也会维护一层轻量的 index_id 关联关系,用来支持目录加载和查询定位,但这里我不会把它做成过重的执行路径。
按 Index TTL 卸载过期索引
索引到期后,我会按照 Index TTL 去卸载对应 reader,并清理磁盘文件和相关元数据。这里我同样会做一个比较保守的处理,避免刚落盘或者刚加载的索引被误伤,所以不会一到边界就立刻硬删,而是按更稳妥的节奏去回收。
🎈 节点弹性伸缩 – 扩容和缩容
扩容时机
我不会把扩容当成默认动作。只有当索引任务已经无法继续发送,现有 DataPlane 全部都触碰到容量安全线,而且 task 缩小之后仍然放不下时,我才会触发 scale-up。也就是说,扩容的前提不是“任务来了”,而是“现有节点真的都满了,而且已经没有更便宜的调度解法”。
缩容至少等 24 小时
每一个 DataPlane 在我的设计里都有最短生存时长,我把这个时间定成了 24 小时。原因不是拍脑袋,而是业务流量在一天内通常有明显的波峰波谷。如果把缩容门槛设成 2 小时这种较激进的值,那么凌晨低谷期很容易把 DataPlane 回收掉,到了早上或中午流量再起来时又得重新扩容和重建索引,这会明显增加整个系统的 overhead。
两阶段缩容
flowchart LR
A["mark DataPlane"] --> B["wait minimum 24h lifetime"]
B --> C["observe load and index state"]
C --> D{"still removable?"}
D -- no --> E["clear mark"]
D -- yes --> F["delete DataPlane and cleanup metadata"]
缩容不是直接删除,而是两阶段处理:先标记,再等待,最后才删除。如果一个 DataPlane 在等待期内又重新变忙,我就会把标记清除掉,避免系统在日内波动里来回抖动。
💿 本地元数据存储
这套系统里我没有试图用一种存储解决全部问题,而是根据访问模式去拆分。整体上我用的是 SQLite 和 SledDB 两类存储:前者更适合单个 DataPlane 内部的本地状态和任务持久化,后者更适合 ControlPlane 侧的轻量关系和状态索引。
SQLite 使用场景
在单个 DataPlane 内部,我更偏向用 SQLite 来存储本地任务和状态信息。原因很简单,这类数据需要的是稳定、直接、易恢复,尤其是 invidx-build 里的任务持久化、重试状态和单个 DataPlane 自己的运行信息,放在 SQLite 里会比较顺手,重启恢复也更直接。
为什么用 SledDB
在 ControlPlane 侧,我更愿意用 SledDB 去维护轻量的关系索引,比如 task-id、parquet-id、data-plane-id 这类映射关系,以及一些单独的指标状态。这里我关注的是快速读写、小粒度更新和本地嵌入式使用体验,而不是把它当成一个承载大对象的通用数据库。
SledDB 陷阱
SledDB 虽然很好用,但我在这个项目里也会刻意控制它承载的数据形态。因为它的 CAS 机制会让一些旧版本数据不会立刻 GC,所以不适合往里面塞太大的结构体或者很重的对象。我更倾向于只放整数数组、轻量映射、单个指标状态这类小对象,把真正大的内容或者更本地化的任务状态交给 SQLite。
🏁 最后总结
回头看这个项目,我觉得它真正解决的不是“怎么把 Tantivy 接进来”,而是怎么把下面这些问题串成一套完整方案:
- TimeSeries DB 不应该因为一个时间范围就访问全部 Parquet。
- 索引系统不能只会建索引,还要会规划资源、控制生命周期。
- ControlPlane 要负责全局判断,DataPlane 要负责局部执行。
- 查询优化不能只靠字段匹配,还要把时间顺序和 limit 一起纳入编排。
如果用一句话概括我现在对这套架构的理解,那就是:
“我做的不是一个通用搜索引擎,而是一套围绕 Parquet 裁剪、时间顺序查询和云原生资源调度设计出来的查询前置索引服务。”
它已经能比较完整地解决我当初想解决的问题,但它还远远不是“终态”。真正的价值不是今天这版代码本身,而是我已经把一条能持续演进的架构主线搭出来了。